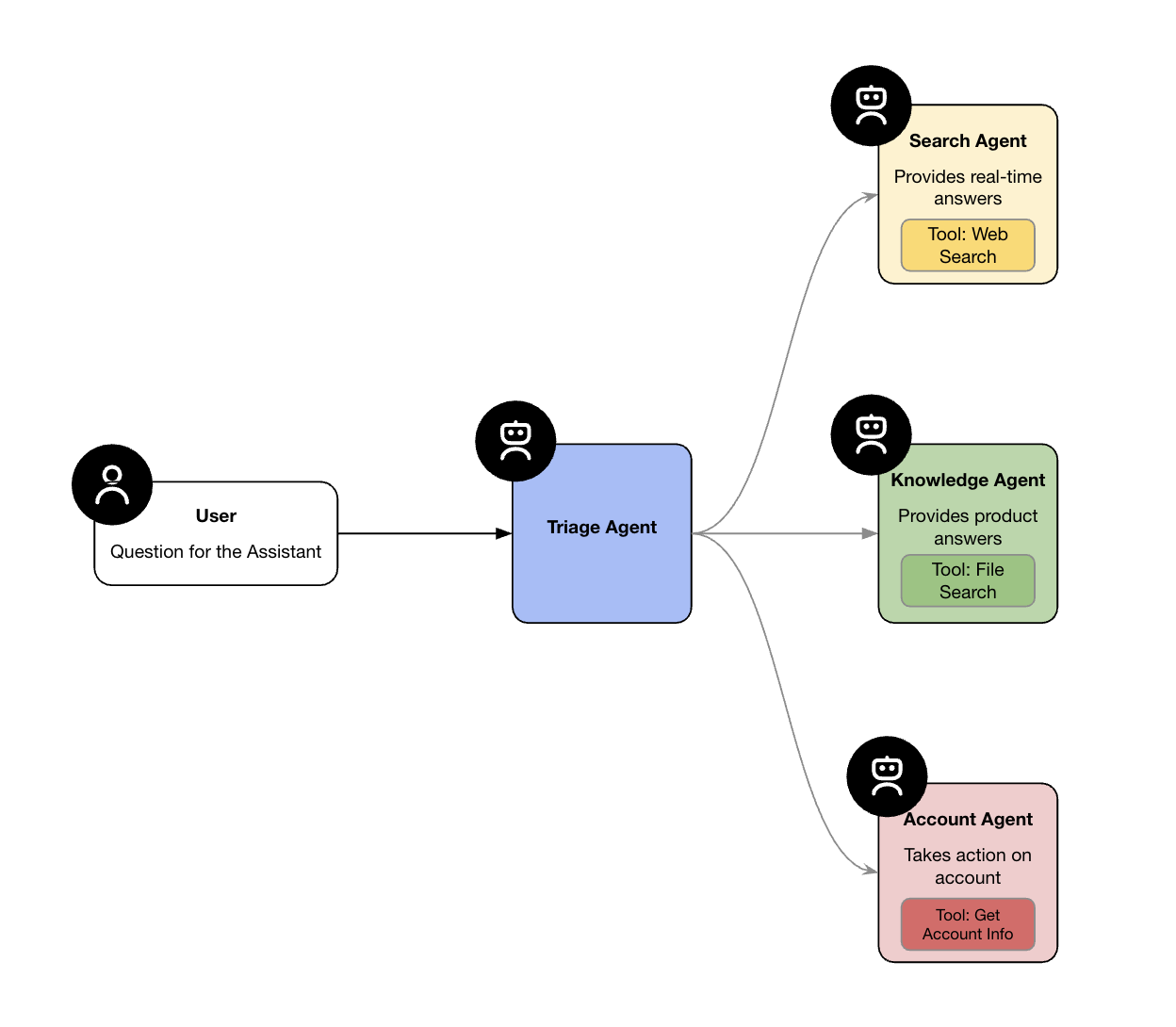
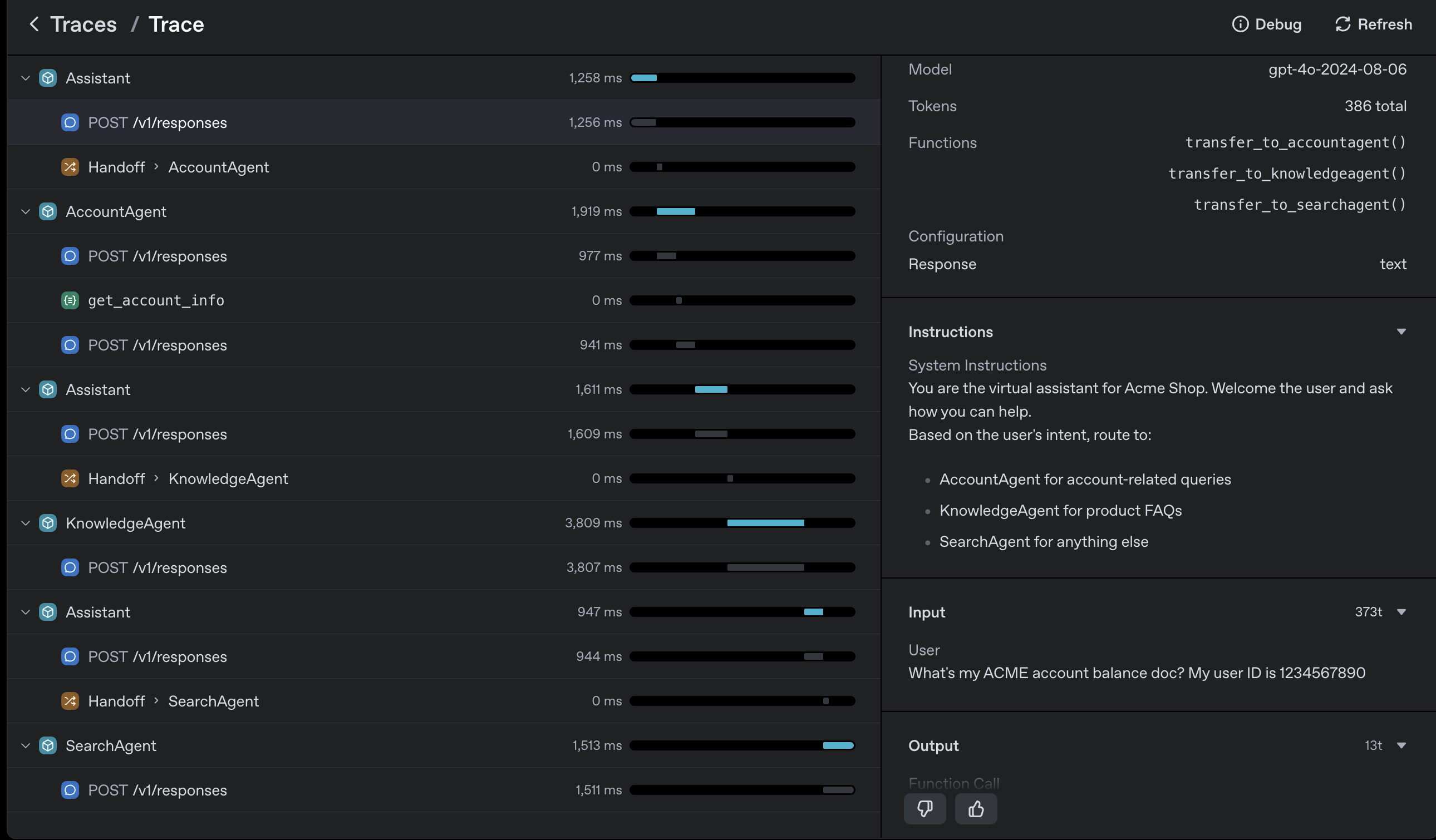
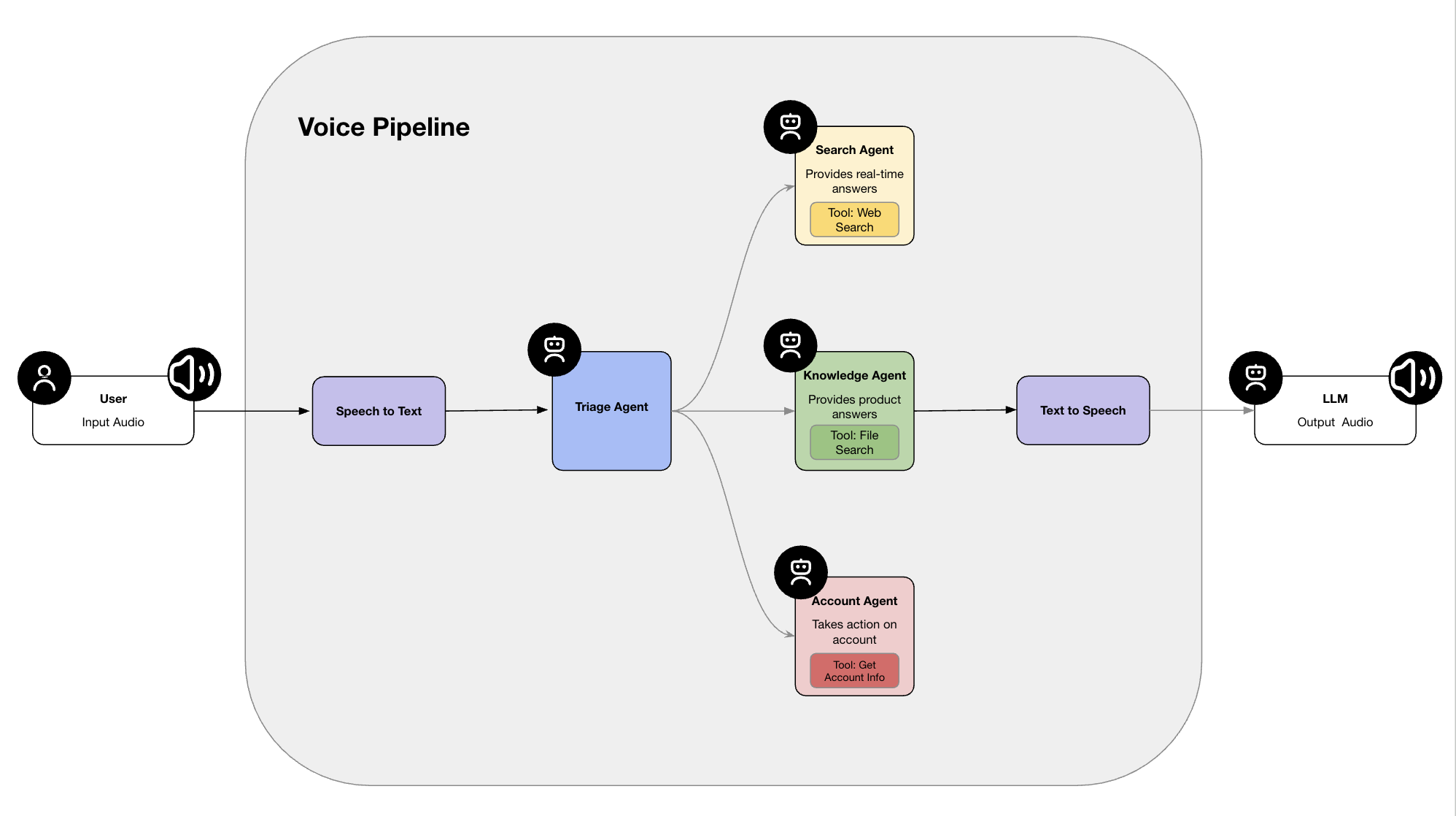
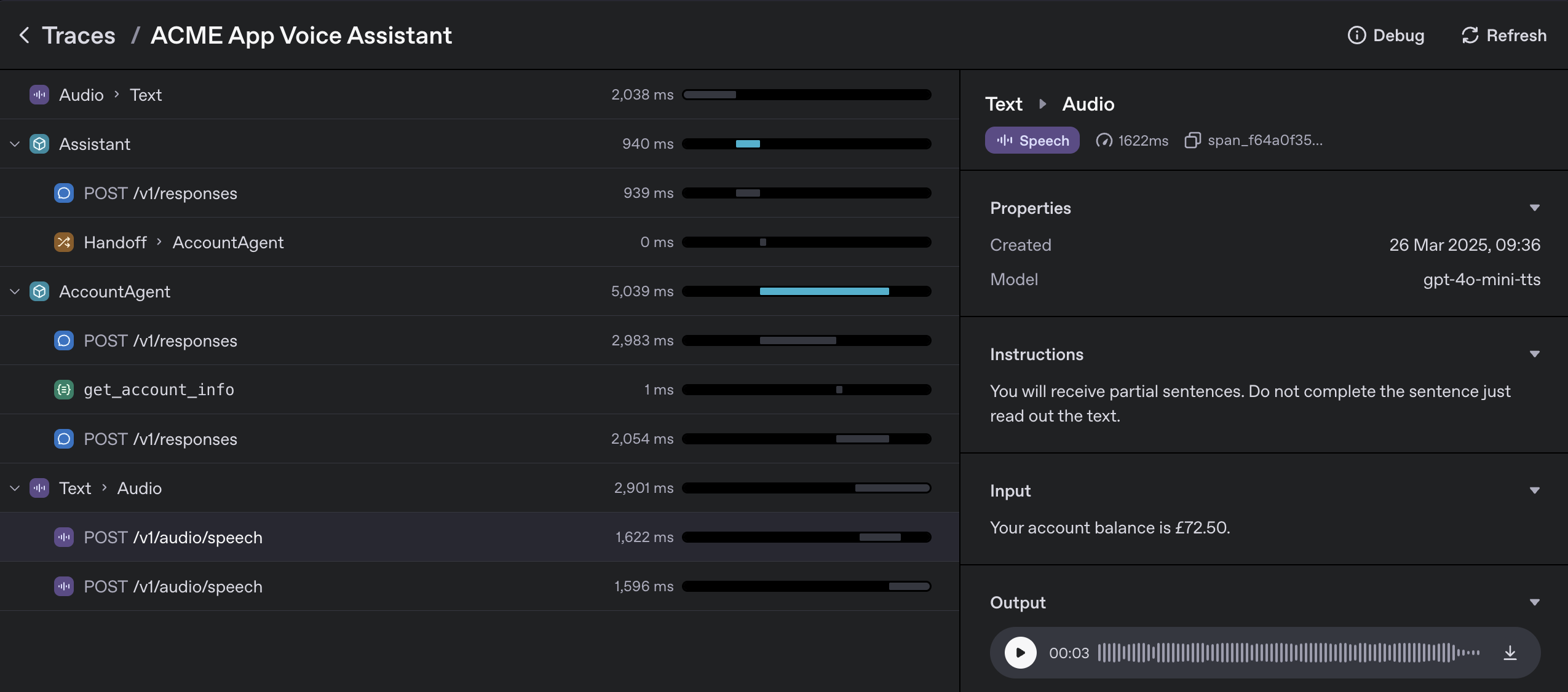
from agents.voice import TTSModelSettings, VoicePipeline, VoicePipelineConfig, SingleAgentVoiceWorkflow, AudioInput
import sounddevice as sd
import numpy as np
# Define custom TTS model settings with the desired instructions
custom_tts_settings = TTSModelSettings(
instructions="Personality: upbeat, friendly, persuasive guide"
"Tone: Friendly, clear, and reassuring, creating a calm atmosphere and making the listener feel confident and comfortable."
"Pronunciation: Clear, articulate, and steady, ensuring each instruction is easily understood while maintaining a natural, conversational flow."
"Tempo: Speak relatively fast, include brief pauses and after before questions"
"Emotion: Warm and supportive, conveying empathy and care, ensuring the listener feels guided and safe throughout the journey."
)
async def voice_assistant_optimized():
samplerate = sd.query_devices(kind='input')['default_samplerate']
voice_pipeline_config = VoicePipelineConfig(tts_settings=custom_tts_settings)
while True:
pipeline = VoicePipeline(workflow=SingleAgentVoiceWorkflow(triage_voice_agent), config=voice_pipeline_config)
# Check for input to either provide voice or exit
cmd = input("Press Enter to speak your query (or type 'esc' to exit): ")
if cmd.lower() == "esc":
print("Exiting...")
break
print("Listening...")
recorded_chunks = []
# Start streaming from microphone until Enter is pressed
with sd.InputStream(samplerate=samplerate, channels=1, dtype='int16', callback=lambda indata, frames, time, status: recorded_chunks.append(indata.copy())):
input()
# Concatenate chunks into single buffer
recording = np.concatenate(recorded_chunks, axis=0)
# Input the buffer and await the result
audio_input = AudioInput(buffer=recording)
with trace("ACME App Optimized Voice Assistant"):
result = await pipeline.run(audio_input)
# Transfer the streamed result into chunks of audio
response_chunks = []
async for event in result.stream():
if event.type == "voice_stream_event_audio":
response_chunks.append(event.data)
response_audio = np.concatenate(response_chunks, axis=0)
# Play response
print("Assistant is responding...")
sd.play(response_audio, samplerate=samplerate)
sd.wait()
print("---")
# Run the voice assistant
await voice_assistant_optimized()