在本笔记本中,我们将研究构建 RAG 管道并使用 LlamaIndex 对其进行评估。它包含以下 3 个部分。
- 理解检索增强生成 (RAG)。
- 使用 LlamaIndex 构建 RAG。
- 使用 LlamaIndex 评估 RAG。
在本笔记本中,我们将研究构建 RAG 管道并使用 LlamaIndex 对其进行评估。它包含以下 3 个部分。
检索增强生成 (RAG)
LLM 是在庞大的数据集上训练的,但这些数据集不包括您的特定数据。检索增强生成 (RAG) 通过在生成过程中动态合并您的数据来解决这个问题。 这不是通过更改 LLM 的训练数据来完成的,而是通过允许模型实时访问和利用您的数据,从而提供更定制化和上下文相关的响应。
在 RAG 中,您的数据被加载并准备好用于查询或“索引”。用户查询作用于索引,索引将您的数据过滤到最相关的上下文中。 然后,此上下文和您的查询与提示一起发送到 LLM,LLM 提供响应。
即使您正在构建的是聊天机器人或代理,您也需要了解将数据导入应用程序的 RAG 技术。
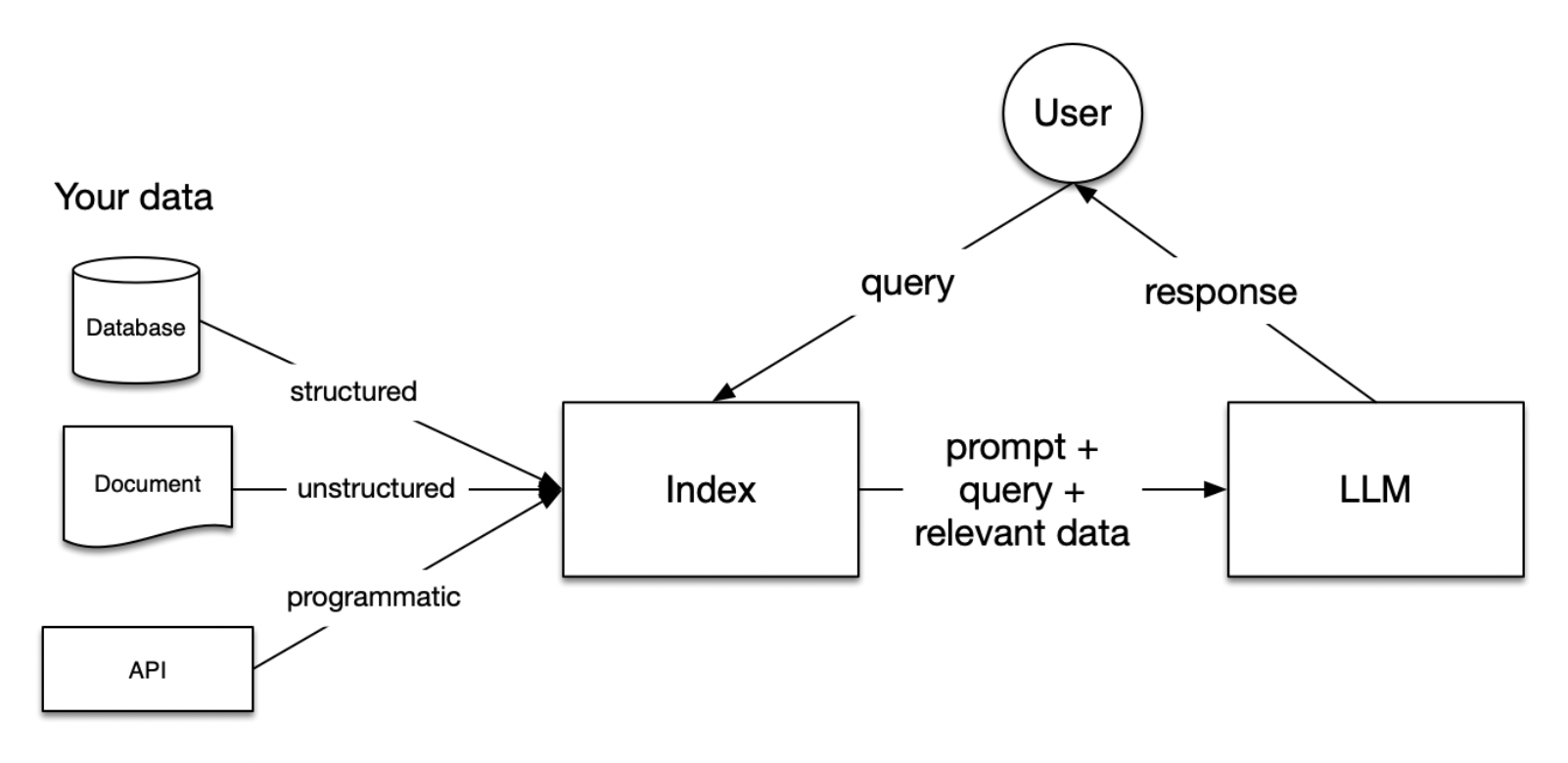
RAG 中的阶段
RAG 中有五个关键阶段,这些阶段将成为您构建的任何更大应用程序的一部分。 这些是
加载: 这指的是从您的数据所在位置(无论是文本文件、PDF、另一个网站、数据库还是 API)将数据导入您的管道。 LlamaHub 提供了数百个连接器可供选择。
索引: 这意味着创建一种数据结构,允许查询数据。 对于 LLM,这几乎总是意味着创建向量嵌入,即数据含义的数值表示,以及许多其他元数据策略,以便轻松准确地找到上下文相关的数据。
存储: 数据索引完成后,您将需要存储您的索引以及任何其他元数据,以避免重新索引的需要。
查询: 对于任何给定的索引策略,您可以使用 LLM 和 LlamaIndex 数据结构进行多种查询,包括子查询、多步查询和混合策略。
评估: 任何管道中的关键步骤是检查其相对于其他策略或在您进行更改时的有效性。 评估提供对查询响应的准确性、忠实度和速度的客观衡量。
现在我们已经了解了 RAG 系统的意义,让我们构建一个简单的 RAG 管道。
!pip install llama-index# The nest_asyncio module enables the nesting of asynchronous functions within an already running async loop.
# This is necessary because Jupyter notebooks inherently operate in an asynchronous loop.
# By applying nest_asyncio, we can run additional async functions within this existing loop without conflicts.
import nest_asyncio
nest_asyncio.apply()
from llama_index.evaluation import generate_question_context_pairs
from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.node_parser import SimpleNodeParser
from llama_index.evaluation import generate_question_context_pairs
from llama_index.evaluation import RetrieverEvaluator
from llama_index.llms import OpenAI
import os
import pandas as pd设置您的 OpenAI API 密钥
os.environ['OPENAI_API_KEY'] = 'YOUR OPENAI API KEY'让我们使用 Paul Graham Essay 文本来构建 RAG 管道。
!mkdir -p 'data/paul_graham/'
!curl 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt' -o 'data/paul_graham/paul_graham_essay.txt' % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 75042 100 75042 0 0 190k 0 --:--:-- --:--:-- --:--:-- 190k--:-- 0:00:03 24586
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
# Define an LLM
llm = OpenAI(model="gpt-4")
# Build index with a chunk_size of 512
node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
nodes = node_parser.get_nodes_from_documents(documents)
vector_index = VectorStoreIndex(nodes)构建 QueryEngine 并开始查询。
query_engine = vector_index.as_query_engine()response_vector = query_engine.query("What did the author do growing up?")检查响应。
response_vector.response'The author wrote short stories and worked on programming, specifically on an IBM 1401 computer using an early version of Fortran.'
默认情况下,它检索 two 个相似的节点/块。 您可以在 vector_index.as_query_engine(similarity_top_k=k) 中修改它。
让我们检查一下每个检索到的节点中的文本。
# First retrieved node
response_vector.source_nodes[0].get_text()'What I Worked On\n\nFebruary 2021\n\nBefore college the two main things I worked on, outside of school, were writing and programming. I didn\'t write essays. I wrote what beginning writers were supposed to write then, and probably still are: short stories. My stories were awful. They had hardly any plot, just characters with strong feelings, which I imagined made them deep.\n\nThe first programs I tried writing were on the IBM 1401 that our school district used for what was then called "data processing." This was in 9th grade, so I was 13 or 14. The school district\'s 1401 happened to be in the basement of our junior high school, and my friend Rich Draves and I got permission to use it. It was like a mini Bond villain\'s lair down there, with all these alien-looking machines — CPU, disk drives, printer, card reader — sitting up on a raised floor under bright fluorescent lights.\n\nThe language we used was an early version of Fortran. You had to type programs on punch cards, then stack them in the card reader and press a button to load the program into memory and run it. The result would ordinarily be to print something on the spectacularly loud printer.\n\nI was puzzled by the 1401. I couldn\'t figure out what to do with it. And in retrospect there\'s not much I could have done with it. The only form of input to programs was data stored on punched cards, and I didn\'t have any data stored on punched cards. The only other option was to do things that didn\'t rely on any input, like calculate approximations of pi, but I didn\'t know enough math to do anything interesting of that type. So I\'m not surprised I can\'t remember any programs I wrote, because they can\'t have done much. My clearest memory is of the moment I learned it was possible for programs not to terminate, when one of mine didn\'t. On a machine without time-sharing, this was a social as well as a technical error, as the data center manager\'s expression made clear.\n\nWith microcomputers, everything changed.'
# Second retrieved node
response_vector.source_nodes[1].get_text()"It felt like I was doing life right. I remember that because I was slightly dismayed at how novel it felt. The good news is that I had more moments like this over the next few years.\n\nIn the summer of 2016 we moved to England. We wanted our kids to see what it was like living in another country, and since I was a British citizen by birth, that seemed the obvious choice. We only meant to stay for a year, but we liked it so much that we still live there. So most of Bel was written in England.\n\nIn the fall of 2019, Bel was finally finished. Like McCarthy's original Lisp, it's a spec rather than an implementation, although like McCarthy's Lisp it's a spec expressed as code.\n\nNow that I could write essays again, I wrote a bunch about topics I'd had stacked up. I kept writing essays through 2020, but I also started to think about other things I could work on. How should I choose what to do? Well, how had I chosen what to work on in the past? I wrote an essay for myself to answer that question, and I was surprised how long and messy the answer turned out to be. If this surprised me, who'd lived it, then I thought perhaps it would be interesting to other people, and encouraging to those with similarly messy lives. So I wrote a more detailed version for others to read, and this is the last sentence of it.\n\n\n\n\n\n\n\n\n\nNotes\n\n[1] My experience skipped a step in the evolution of computers: time-sharing machines with interactive OSes. I went straight from batch processing to microcomputers, which made microcomputers seem all the more exciting.\n\n[2] Italian words for abstract concepts can nearly always be predicted from their English cognates (except for occasional traps like polluzione). It's the everyday words that differ. So if you string together a lot of abstract concepts with a few simple verbs, you can make a little Italian go a long way.\n\n[3] I lived at Piazza San Felice 4, so my walk to the Accademia went straight down the spine of old Florence: past the Pitti, across the bridge, past Orsanmichele, between the Duomo and the Baptistery, and then up Via Ricasoli to Piazza San Marco."
我们已经构建了一个 RAG 管道,现在需要评估其性能。 我们可以使用 LlamaIndex 的核心评估模块来评估我们的 RAG 系统/查询引擎。 让我们研究如何利用这些工具来量化我们的检索增强生成系统的质量。
评估应作为评估 RAG 应用程序的主要指标。 它确定管道是否会根据数据源和一系列查询生成准确的响应。
虽然在一开始检查单个查询和响应是有益的,但随着边缘案例和故障数量的增加,这种方法可能会变得不切实际。 相反,建立一套摘要指标或自动化评估可能更有效。 这些工具可以提供对整体系统性能的深入了解,并指出可能需要更仔细审查的特定领域。
在 RAG 系统中,评估侧重于两个关键方面
为了评估 RAG 系统,必须有能够获取正确上下文并随后生成适当响应的查询。 LlamaIndex 提供了一个 generate_question_context_pairs 模块,专门用于制作问题和上下文对,这些问题和上下文对可用于评估检索和响应评估的 RAG 系统。 有关问题生成的更多详细信息,请参阅文档。
qa_dataset = generate_question_context_pairs(
nodes,
llm=llm,
num_questions_per_chunk=2
)100%|██████████| 58/58 [06:26<00:00, 6.67s/it]
我们现在已准备好进行检索评估。 我们将使用我们生成的评估数据集执行我们的 RetrieverEvaluator。
我们首先创建 Retriever,然后定义两个函数:get_eval_results,它在数据集上运行我们的检索器,以及 display_results,它呈现评估的结果。
让我们创建检索器。
retriever = vector_index.as_retriever(similarity_top_k=2)定义 RetrieverEvaluator。 我们使用命中率和 MRR 指标来评估我们的检索器。
命中率
命中率计算在 top-k 检索到的文档中找到正确答案的查询的分数。 简单来说,就是我们的系统在几次猜测中正确命中的频率。
平均倒数排名 (MRR)
对于每个查询,MRR 通过查看排名最高的文档的排名来评估系统的准确性。 具体来说,它是所有查询中这些排名的倒数的平均值。 因此,如果第一个相关文档是首要结果,则倒数排名为 1; 如果它是第二个,则倒数排名为 1/2,依此类推。
让我们检查这些指标以检查检索器的性能。
retriever_evaluator = RetrieverEvaluator.from_metric_names(
["mrr", "hit_rate"], retriever=retriever
)# Evaluate
eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)让我们定义一个函数,以表格格式显示检索评估结果。
def display_results(name, eval_results):
"""Display results from evaluate."""
metric_dicts = []
for eval_result in eval_results:
metric_dict = eval_result.metric_vals_dict
metric_dicts.append(metric_dict)
full_df = pd.DataFrame(metric_dicts)
hit_rate = full_df["hit_rate"].mean()
mrr = full_df["mrr"].mean()
metric_df = pd.DataFrame(
{"Retriever Name": [name], "Hit Rate": [hit_rate], "MRR": [mrr]}
)
return metric_dfdisplay_results("OpenAI Embedding Retriever", eval_results)| 检索器名称 | 命中率 | MRR | |
|---|---|---|---|
| 0 | OpenAI 嵌入检索器 | 0.758621 | 0.62069 |
使用 OpenAI 嵌入的检索器表现出命中率为 0.7586 的性能,而 MRR 为 0.6206,这表明在确保最相关的结果出现在顶部方面还有改进空间。 MRR 小于命中率的观察结果表明,排名靠前的结果并不总是最相关的。 提高 MRR 可能涉及使用重新排序器,重新排序器可以优化检索到的文档的顺序。 要更深入地了解重新排序器如何优化检索指标,请参阅我们的博客文章中的详细讨论。
# Get the list of queries from the above created dataset
queries = list(qa_dataset.queries.values())让我们从 FaithfulnessEvaluator 开始。
我们将使用 gpt-3.5-turbo 生成给定查询的响应,并使用 gpt-4 进行评估。
让我们分别为 gpt-3.5-turbo 和 gpt-4 创建 service_context。
# gpt-3.5-turbo
gpt35 = OpenAI(temperature=0, model="gpt-3.5-turbo")
service_context_gpt35 = ServiceContext.from_defaults(llm=gpt35)
# gpt-4
gpt4 = OpenAI(temperature=0, model="gpt-4")
service_context_gpt4 = ServiceContext.from_defaults(llm=gpt4)使用 gpt-3.5-turbo service_context 创建 QueryEngine,以生成查询的响应。
vector_index = VectorStoreIndex(nodes, service_context = service_context_gpt35)
query_engine = vector_index.as_query_engine()创建一个 FaithfulnessEvaluator。
from llama_index.evaluation import FaithfulnessEvaluator
faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)让我们评估一个问题。
eval_query = queries[10]
eval_query"Based on the author's experience and observations, why did he consider the AI practices during his first year of grad school as a hoax? Provide specific examples from the text to support your answer."
首先生成响应,然后使用 faithful evaluator。
response_vector = query_engine.query(eval_query)# Compute faithfulness evaluation
eval_result = faithfulness_gpt4.evaluate_response(response=response_vector)# You can check passing parameter in eval_result if it passed the evaluation.
eval_result.passingTrue
RelevancyEvaluator 可用于衡量响应和源节点(检索到的上下文)是否与查询匹配。 有助于查看响应是否真正回答了查询。
实例化 RelevancyEvaluator 以使用 gpt-4 进行相关性评估
from llama_index.evaluation import RelevancyEvaluator
relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)让我们对其中一个查询进行相关性评估。
# Pick a query
query = queries[10]
query"Based on the author's experience and observations, why did he consider the AI practices during his first year of grad school as a hoax? Provide specific examples from the text to support your answer."
# Generate response.
# response_vector has response and source nodes (retrieved context)
response_vector = query_engine.query(query)
# Relevancy evaluation
eval_result = relevancy_gpt4.evaluate_response(
query=query, response=response_vector
)# You can check passing parameter in eval_result if it passed the evaluation.
eval_result.passingTrue
# You can get the feedback for the evaluation.
eval_result.feedback'YES'
现在我们已经独立完成了 FaithFulness 和 Relevancy Evaluation。 LlamaIndex 具有 BatchEvalRunner,可以批量方式计算多个评估。
from llama_index.evaluation import BatchEvalRunner
# Let's pick top 10 queries to do evaluation
batch_eval_queries = queries[:10]
# Initiate BatchEvalRunner to compute FaithFulness and Relevancy Evaluation.
runner = BatchEvalRunner(
{"faithfulness": faithfulness_gpt4, "relevancy": relevancy_gpt4},
workers=8,
)
# Compute evaluation
eval_results = await runner.aevaluate_queries(
query_engine, queries=batch_eval_queries
)# Let's get faithfulness score
faithfulness_score = sum(result.passing for result in eval_results['faithfulness']) / len(eval_results['faithfulness'])
faithfulness_score1.0
# Let's get relevancy score
relevancy_score = sum(result.passing for result in eval_results['relevancy']) / len(eval_results['relevancy'])
relevancy_score
1.0
1.0 的 Faithfulness 分数表示生成的答案不包含任何幻觉,并且完全基于检索到的上下文。
1.0 的 Relevancy 分数表明生成的答案始终与检索到的上下文和查询保持一致。
在本笔记本中,我们探讨了如何使用 LlamaIndex 构建和评估 RAG 管道,特别关注评估管道中的检索系统和生成的响应。
LlamaIndex 还提供了各种其他评估模块,您可以在此处进一步探索