本页面为开发者构建特定应用程序的 GPT Action 提供说明和指南。在继续之前,请务必先熟悉以下信息
此解决方案使 GPT Action 能够从 Redshift 检索数据并执行数据分析。它使用 AWS Functions,从 AWS 生态系统和网络执行每个操作。中间件(AWS 函数)将执行 SQL 查询,等待其完成并将数据作为文件返回。提供的代码仅供参考,应根据您的需求进行修改。
此解决方案使用在 Actions 中检索文件并像直接将它们上传到对话中一样使用它们的能力。
此解决方案突出了与 Redshift serverless 的连接,与预置 Redshift 的集成在检索网络和设置连接方面可能略有不同,但总体代码和(最小)集成应是相似的。
价值 & 示例业务用例
价值:利用 ChatGPT 的自然语言能力连接到 Redshift 的 DWH。
示例用例:
- 数据科学家可以使用 ChatGPT 的数据分析连接到表并运行数据分析
- 普通数据用户可以询问有关其交易数据的基本问题
- 用户可以更好地了解其数据和潜在的异常情况
应用程序信息
应用程序先决条件
在开始之前,请确保:
- 您有权访问 Redshift 环境
- 您有权在同一 VPC(虚拟私有网络)中部署 AWS 函数
- 您的 AWS CLI 已通过身份验证
中间件信息
安装所需的库
中间件功能
要创建函数,请按照AWS Middleware Action cookbook中的步骤操作。
要专门部署连接到 Redshift 的应用程序,请使用以下代码,而不是 Middleware AWS Function cookbook 中引用的“hello-world”GitHub 存储库。您可以克隆存储库,也可以获取下面粘贴的代码并根据您的需求进行修改。
此代码旨在提供方向性指导 - 虽然它应该可以开箱即用,但它的设计目的是根据您的需求进行自定义(请参阅本文档末尾的示例)。
要获取代码,您可以克隆 openai-cookbook 存储库并导航到 redshift-middleware 目录
git clone https://github.com/pap-openai/redshift-middleware
cd redshift-middlewareimport json
import psycopg2
import os
import base64
import tempfile
import csv
# Fetch Redshift credentials from environment variables
host = os.environ['REDSHIFT_HOST']
port = os.environ['REDSHIFT_PORT']
user = os.environ['REDSHIFT_USER']
password = os.environ['REDSHIFT_PASSWORD']
database = os.environ['REDSHIFT_DB']
def execute_statement(sql_statement):
try:
# Establish connection
conn = psycopg2.connect(
host=host,
port=port,
user=user,
password=password,
dbname=database
)
cur = conn.cursor()
cur.execute(sql_statement)
conn.commit()
# Fetch all results
if cur.description:
columns = [desc[0] for desc in cur.description]
result = cur.fetchall()
else:
columns = []
result = []
cur.close()
conn.close()
return columns, result
except Exception as e:
raise Exception(f"Database query failed: {str(e)}")
def lambda_handler(event, context):
try:
data = json.loads(event['body'])
sql_statement = data['sql_statement']
# Execute the statement and fetch results
columns, result = execute_statement(sql_statement)
# Create a temporary file to save the result as CSV
with tempfile.NamedTemporaryFile(delete=False, mode='w', suffix='.csv', newline='') as tmp_file:
csv_writer = csv.writer(tmp_file)
if columns:
csv_writer.writerow(columns) # Write the header
csv_writer.writerows(result) # Write all rows
tmp_file_path = tmp_file.name
# Read the file and encode its content to base64
with open(tmp_file_path, 'rb') as f:
file_content = f.read()
encoded_content = base64.b64encode(file_content).decode('utf-8')
response = {
'openaiFileResponse': [
{
'name': 'query_result.csv',
'mime_type': 'text/csv',
'content': encoded_content
}
]
}
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps(response)
}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps({'error': str(e)})
}
检索 VPC 信息
我们将需要将我们的函数连接到 Redshift,因此我们需要找到 Redshift 使用的网络。您可以在 AWS 控制台上的 Redshift 界面中找到此信息,在 Amazon Redshift Serverless > Workgroup 配置 > your_workgroup > 数据访问下,或通过 CLI 找到
aws redshift-serverless get-workgroup --workgroup-name default-workgroup --query 'workgroup.{address: endpoint.address, port: endpoint.port, SecurityGroupIds: securityGroupIds, SubnetIds: subnetIds}'设置 AWS 函数
将 env.sample.yaml 复制到 env.yaml 并替换为上面获得的值。您将需要一个有权访问您的数据库/模式的 Redshift 用户。
cp env.sample.yaml env.yaml在 env.yaml 中填写上一个命令检索到的值以及您的 Redshift 凭据。或者,您可以手动创建一个名为 env.yaml 的文件并填写以下变量
RedshiftHost: default-workgroup.xxxxx.{region}.redshift-serverless.amazonaws.com
RedshiftPort: 5439
RedshiftUser: username
RedshiftPassword: password
RedshiftDb: my-db
SecurityGroupId: sg-xx
SubnetId1: subnet-xx
SubnetId2: subnet-xx
SubnetId3: subnet-xx
SubnetId4: subnet-xx
SubnetId5: subnet-xx
SubnetId6: subnet-xx此文件将用于使用参数部署您的函数,如下所示
PARAM_FILE="env.yaml"
PARAMS=$(yq eval -o=json $PARAM_FILE | jq -r 'to_entries | map("\(.key)=\(.value|tostring)") | join(" ")')
sam deploy --template-file template.yaml --stack-name redshift-middleware --capabilities CAPABILITY_IAM --parameter-overrides $PARAMStemplate.yaml 具有以下内容
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
redshift-middleware
Middleware to fetch RedShift data and return it through HTTP as files
Globals:
Function:
Timeout: 3
Parameters:
RedshiftHost:
Type: String
RedshiftPort:
Type: String
RedshiftUser:
Type: String
RedshiftPassword:
Type: String
RedshiftDb:
Type: String
SecurityGroupId:
Type: String
SubnetId1:
Type: String
SubnetId2:
Type: String
SubnetId3:
Type: String
SubnetId4:
Type: String
SubnetId5:
Type: String
SubnetId6:
Type: String
CognitoUserPoolName:
Type: String
Default: MyCognitoUserPool
CognitoUserPoolClientName:
Type: String
Default: MyCognitoUserPoolClient
Resources:
MyCognitoUserPool:
Type: AWS::Cognito::UserPool
Properties:
UserPoolName: !Ref CognitoUserPoolName
Policies:
PasswordPolicy:
MinimumLength: 8
UsernameAttributes:
- email
Schema:
- AttributeDataType: String
Name: email
Required: false
MyCognitoUserPoolClient:
Type: AWS::Cognito::UserPoolClient
Properties:
UserPoolId: !Ref MyCognitoUserPool
ClientName: !Ref CognitoUserPoolClientName
GenerateSecret: true
RedshiftMiddlewareApi:
Type: AWS::Serverless::Api
Properties:
StageName: Prod
Cors: "'*'"
Auth:
DefaultAuthorizer: MyCognitoAuthorizer
Authorizers:
MyCognitoAuthorizer:
AuthorizationScopes:
- openid
- email
- profile
UserPoolArn: !GetAtt MyCognitoUserPool.Arn
RedshiftMiddlewareFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: redshift-middleware/
Handler: app.lambda_handler
Runtime: python3.11
Timeout: 45
Architectures:
- x86_64
Events:
SqlStatement:
Type: Api
Properties:
Path: /sql_statement
Method: post
RestApiId: !Ref RedshiftMiddlewareApi
Environment:
Variables:
REDSHIFT_HOST: !Ref RedshiftHost
REDSHIFT_PORT: !Ref RedshiftPort
REDSHIFT_USER: !Ref RedshiftUser
REDSHIFT_PASSWORD: !Ref RedshiftPassword
REDSHIFT_DB: !Ref RedshiftDb
VpcConfig:
SecurityGroupIds:
- !Ref SecurityGroupId
SubnetIds:
- !Ref SubnetId1
- !Ref SubnetId2
- !Ref SubnetId3
- !Ref SubnetId4
- !Ref SubnetId5
- !Ref SubnetId6
Outputs:
RedshiftMiddlewareApi:
Description: "API Gateway endpoint URL for Prod stage for SQL Statement function"
Value: !Sub "https://${RedshiftMiddlewareApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/sql_statement/"
RedshiftMiddlewareFunction:
Description: "SQL Statement Lambda Function ARN"
Value: !GetAtt RedshiftMiddlewareFunction.Arn
RedshiftMiddlewareFunctionIamRole:
Description: "Implicit IAM Role created for SQL Statement function"
Value: !GetAtt RedshiftMiddlewareFunctionRole.Arn
CognitoUserPoolArn:
Description: "ARN of the Cognito User Pool"
Value: !GetAtt MyCognitoUserPool.Arn
从上一个命令输出中检索 URL 信息,然后您可以运行 cURL 请求,该请求应以文件格式返回数据
curl -X POST https://<your_url>/Prod/sql_statement/ \
-H "Content-Type: application/json" \
-d '{ "sql_statement": "SELECT * FROM customers LIMIT 10", "workgroup_name": "default-workgroup", "database_name": "pap-db" }'ChatGPT 步骤
自定义 GPT 指令
创建自定义 GPT 后,将以下文本复制到“Instructions”面板中。
**Context**: You are an expert at writing Redshift SQL queries. You will initially retrieve the table schema that you will use thoroughly. Every attributes, table names or data type will be known by you.
**Instructions**:
1. No matter the user's question, start by running `runQuery` operation using this query: "SELECT table_name, column_name FROM INFORMATION_SCHEMA.COLUMNS WHERE table_schema = 'public' ORDER BY table_name, ordinal_position;" It will help you understand how to query the data. A CSV will be returned with all the attributes and their table. Make sure to read it fully and understand all available tables & their attributes before querying. You don't have to show this to the user.
2. Convert the user's question into a SQL statement that leverages the step above and run the `runQuery` operation on that SQL statement to confirm the query works. Let the user know which table you will use/query.
3. Execute the query and show him the data. Show only the first few rows.
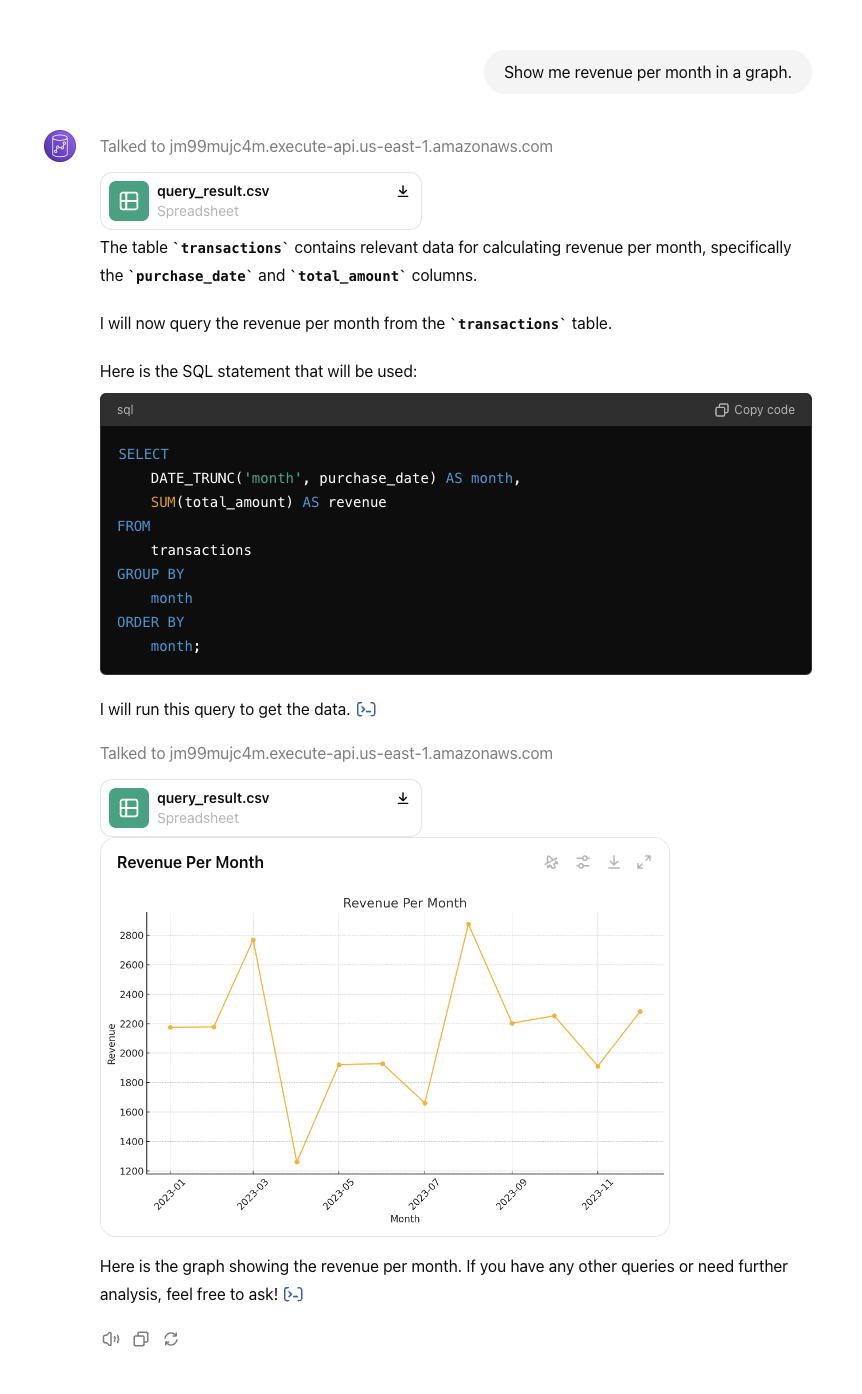
**Additional Notes**: If the user says "Let's get started", explain they can ask a question they want answered about data that we have access to. If the user has no ideas, suggest that we have transactions data they can query - ask if they want you to query that.
**Important**: Never make up a table name or table attribute. If you don't know, go back to the data you've retrieved to check what is available. If you think no table or attribute is available, then tell the user you can't perform this query for them.OpenAPI 架构
创建自定义 GPT 后,将以下文本复制到“Actions”面板中。
这需要一个与我们的文档 此处中的文件检索结构匹配的响应,并将 query 作为参数传递以执行。
请务必按照AWS Middleware cookbook中的步骤设置身份验证。
请务必根据您的函数部署切换函数应用程序名称。
openapi: 3.1.0
info:
title: SQL Execution API
description: API to execute SQL statements and return results as a file.
version: 1.0.0
servers:
- url: {your_function_url}/Prod
description: Production server
paths:
/sql_statement:
post:
operationId: executeSqlStatement
summary: Executes a SQL statement and returns the result as a file.
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
sql_statement:
type: string
description: The SQL statement to execute.
example: SELECT * FROM customers LIMIT 10
required:
- sql_statement
responses:
'200':
description: The SQL query result as a JSON file.
content:
application/json:
schema:
type: object
properties:
openaiFileResponse:
type: array
items:
type: object
properties:
name:
type: string
description: The name of the file.
example: query_result.json
mime_type:
type: string
description: The MIME type of the file.
example: application/json
content:
type: string
description: The base64 encoded content of the file.
format: byte
example: eyJrZXkiOiJ2YWx1ZSJ9
'500':
description: Error response
content:
application/json:
schema:
type: object
properties:
error:
type: string
description: Error message.
example: Database query failed error details
结论
您现在已经部署了一个 GPT,它在 AWS 中以经过身份验证的方式使用中间件,能够连接到 Redshift。具有访问权限(在 Cognito 中)的用户现在可以查询您的数据库以执行数据分析任务