本页面为开发者构建特定应用程序的 GPT Action 提供说明和指南。在继续之前,请务必先熟悉以下信息
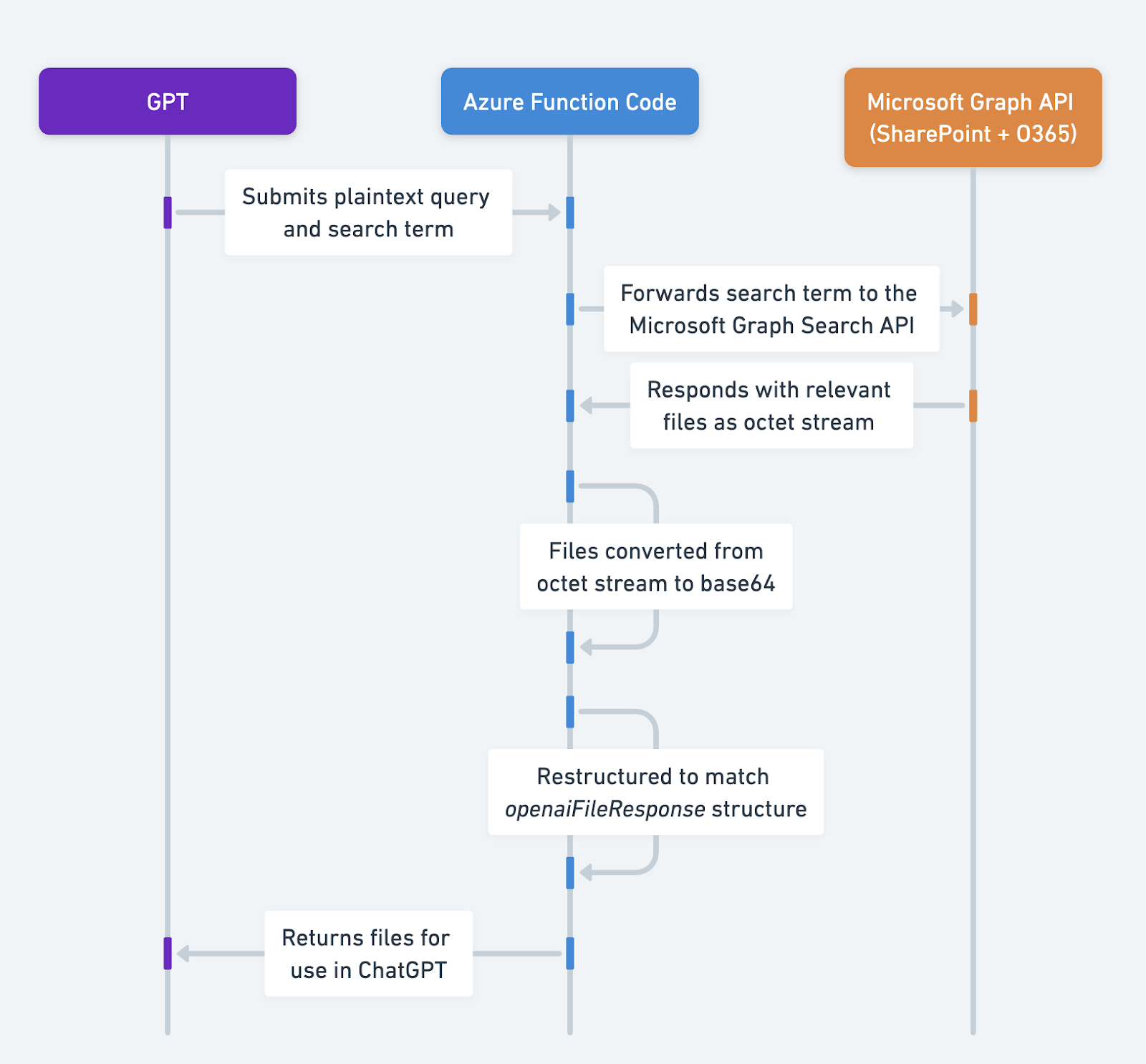
此解决方案使 GPT Action 能够使用用户可以在 SharePoint 或 Office365 中访问的文件上下文来回答用户的问题,使用 Microsoft Graph API 的 搜索功能 和 检索文件 的能力。它使用 Azure 函数来处理 Graph API 响应,并将其转换为人类可读的格式,或以 ChatGPT 可以理解的方式进行结构化。此代码旨在提供方向性指导,您应该根据自己的需求进行修改。
此解决方案利用了 Actions 中检索文件 的能力,并像直接上传到对话一样使用它们。 Azure 函数返回 ChatGPT 转换为文件的 base64 字符串。此解决方案可以处理结构化和非结构化数据,但确实存在大小和容量限制(请参阅 此处 的文档)
价值 + 示例业务用例
价值:用户现在可以利用 ChatGPT 的自然语言能力直接连接到 Sharpeoint 中的文件
示例用例:
- 用户需要查找哪些文件与特定主题相关
- 用户需要一个关键问题的答案,该问题埋藏在文档深处
架构 / 示例
此解决方案使用 Node.js Azure 函数,根据登录用户
-
根据用户的初始问题,搜索用户有权访问的相关文件。
-
对于找到的每个文件,将其转换为 base64 字符串。
-
按照 ChatGPT 期望的结构格式化数据,此处。
-
将其返回给 ChatGPT。然后,GPT 可以像您将其上传到对话一样使用这些文件。
应用程序信息
应用程序关键链接
在开始之前,请查看应用程序中的这些链接
应用程序先决条件
在开始之前,请确保在您的应用程序环境中完成以下步骤
- 访问 SharePoint 环境
- Postman(以及 API 和 OAuth 的知识)
中间件信息
如果您遵循 搜索概念文件指南,则 Microsoft Graph Search API 返回符合条件的文件引用,但不返回文件内容本身。因此,需要中间件,而不是直接访问 MSFT 端点。
我们需要重构来自该 API 的响应,使其与 此处 概述的 openaiFileResponse 中的预期结构相匹配。
其他步骤
设置 Azure 函数
- 使用 Azure 函数 cookbook 中的步骤设置 Azure 函数
添加函数代码
现在您有了一个经过身份验证的 Azure 函数,我们可以更新该函数以搜索 SharePoint / O365
- 转到您的测试函数,并将来自 此文件 的代码粘贴到其中。保存函数。
此代码旨在提供方向性指导 - 虽然它应该可以开箱即用,但它旨在根据您的需求进行定制(请参阅本文档末尾的示例)。
-
通过转到左侧 设置 下的 配置 选项卡,设置以下环境变量。请注意,根据您的 Azure UI,这可能直接列在 环境变量 中。
-
TENANT_ID:从上一节复制 -
CLIENT_ID:从上一节复制
-
-
转到 开发工具 下的 控制台 选项卡
-
在控制台中安装以下软件包
-
npm install @microsoft/microsoft-graph-client -
npm install axios
-
-
-
完成后,再次尝试从 Postman 调用该函数(POST 调用),将以下内容放入正文中(使用您认为会生成响应的查询和搜索词)。
{ "searchTerm": "<choose a search term>" } -
如果您收到响应,则可以将其与自定义 GPT 一起设置了!有关设置此功能的更多详细信息,请参阅 Azure 函数页面的 ChatGPT 部分
更详细的演练
以下内容演练了此解决方案独有的设置说明和演练。您可以在 此处 找到完整代码。
代码演练
以下内容演练了函数的不同部分。在开始之前,请确保已安装所需的软件包并设置了环境变量(请参阅“安装步骤”部分)。
实施身份验证
下面我们有一些辅助函数,将在函数中使用它们。
初始化 Microsoft Graph 客户端
创建一个函数,以使用访问令牌初始化 Graph 客户端。这将用于搜索 Office 365 和 SharePoint。
const { Client } = require('@microsoft/microsoft-graph-client');
function initGraphClient(accessToken) {
return Client.init({
authProvider: (done) => {
done(null, accessToken);
}
});
}获取代表 (OBO) 令牌
此函数使用现有的持有者令牌从 Microsoft 的身份平台请求 OBO 令牌。这使得凭据能够传递,以确保搜索仅返回登录用户可以访问的文件。
const axios = require('axios');
const qs = require('querystring');
async function getOboToken(userAccessToken) {
const { TENANT_ID, CLIENT_ID, MICROSOFT_PROVIDER_AUTHENTICATION_SECRET } = process.env;
const params = {
client_id: CLIENT_ID,
client_secret: MICROSOFT_PROVIDER_AUTHENTICATION_SECRET,
grant_type: 'urn:ietf:params:oauth:grant-type:jwt-bearer',
assertion: userAccessToken,
requested_token_use: 'on_behalf_of',
scope: 'https://graph.microsoft.com/.default'
};
const url = `https\://login.microsoftonline.com/${TENANT_ID}/oauth2/v2.0/token`;
try {
const response = await axios.post(url, qs.stringify(params), {
headers: { 'Content-Type': 'application/x-www-form-urlencoded' }
});
return response.data.access\_token;
} catch (error) {
console.error('Error obtaining OBO token:', error.response?.data || error.message);
throw error;
}
}从 O365 / SharePoint 项目检索内容
此函数获取驱动器项目的内容,将其转换为 base64 字符串,并重构以匹配 openaiFileResponse 格式。
const getDriveItemContent = async (client, driveId, itemId, name) => {
try
const filePath = `/drives/${driveId}/items/${itemId}`;
const downloadPath = filePath + `/content`
// this is where we get the contents and convert to base64
const fileStream = await client.api(downloadPath).getStream();
let chunks = [];
for await (let chunk of fileStream) {
chunks.push(chunk);
}
const base64String = Buffer.concat(chunks).toString('base64');
// this is where we get the other metadata to include in response
const file = await client.api(filePath).get();
const mime_type = file.file.mimeType;
const name = file.name;
return {"name":name, "mime_type":mime_type, "content":base64String}
} catch (error) {
console.error('Error fetching drive content:', error);
throw new Error(`Failed to fetch content for ${name}: ${error.message}`);
}创建 Azure 函数以处理请求
现在我们有了所有这些辅助函数,Azure 函数将通过验证用户身份、执行搜索以及迭代搜索结果来提取文本并将文本的相关部分检索到 GPT,从而协调流程。
处理 HTTP 请求: 该函数首先从 HTTP 请求中提取 query 和 searchTerm。它检查 Authorization 标头是否存在并提取持有者令牌。
身份验证: 使用持有者令牌,它使用上面定义的 getOboToken 从 Microsoft 的身份平台获取 OBO 令牌。
初始化 Graph 客户端: 使用 OBO 令牌,它使用上面定义的 initGraphClient 初始化 Microsoft Graph 客户端。
文档搜索: 它构造一个搜索查询并将其发送到 Microsoft Graph API,以根据 searchTerm 查找文档。
文档处理:对于搜索返回的每个文档
-
它使用 getDriveItemContent 检索文档内容。
-
它将文档转换为 base64 字符串并将其重构为匹配
openaiFileResponse结构。
响应:该函数在 HTTP 响应中将它们发送回去。
module.exports = async function (context, req) {
// const query = req.query.query || (req.body && req.body.query);
const searchTerm = req.query.searchTerm || (req.body && req.body.searchTerm);
if (!req.headers.authorization) {
context.res = {
status: 400,
body: 'Authorization header is missing'
};
return;
}
/// The below takes the token passed to the function, to use to get an OBO token.
const bearerToken = req.headers.authorization.split(' ')[1];
let accessToken;
try {
accessToken = await getOboToken(bearerToken);
} catch (error) {
context.res = {
status: 500,
body: `Failed to obtain OBO token: ${error.message}`
};
return;
}
// Initialize the Graph Client using the initGraphClient function defined above
let client = initGraphClient(accessToken);
// this is the search body to be used in the Microsft Graph Search API: https://learn.microsoft.com/en-us/graph/search-concept-files
const requestBody = {
requests: [
{
entityTypes: ['driveItem'],
query: {
queryString: searchTerm
},
from: 0,
// the below is set to summarize the top 10 search results from the Graph API, but can configure based on your documents.
size: 10
}
]
};
try {
// This is where we are doing the search
const list = await client.api('/search/query').post(requestBody);
const processList = async () => {
// This will go through and for each search response, grab the contents of the file and summarize with gpt-3.5-turbo
const results = [];
await Promise.all(list.value[0].hitsContainers.map(async (container) => {
for (const hit of container.hits) {
if (hit.resource["@odata.type"] === "#microsoft.graph.driveItem") {
const { name, id } = hit.resource;
// The below is where the file lives
const driveId = hit.resource.parentReference.driveId;
// we use the helper function we defined above to get the contents, convert to base64, and restructure it
const contents = await getDriveItemContent(client, driveId, id, name);
results.push(contents)
}
}));
return results;
};
let results;
if (list.value[0].hitsContainers[0].total == 0) {
// Return no results found to the API if the Microsoft Graph API returns no results
results = 'No results found';
} else {
// If the Microsoft Graph API does return results, then run processList to iterate through.
results = await processList();
// this is where we structure the response so ChatGPT knows they are files
results = {'openaiFileResponse': results}
}
context.res = {
status: 200,
body: results
};
} catch (error) {
context.res = {
status: 500,
body: `Error performing search or processing results: ${error.message}`,
};
}
};自定义
以下是一些潜在的自定义领域。
-
您可以自定义 GPT 提示,以便在未找到任何内容时再次搜索一定次数。
-
您可以通过自定义搜索查询来定制代码,使其仅搜索特定的 SharePoint 站点或 O365 驱动器。这将有助于集中搜索并改进检索。当前设置的函数会查找登录用户可以访问的所有文件。
-
您可以更新代码以仅返回某些类型的文件。例如,仅返回结构化数据/ CSV。
-
您可以自定义在调用 Microsoft Graph 时搜索的文件数量。请注意,根据 此处 的文档,您最多只能放置 10 个文件。
注意事项
请注意,Actions 的所有相同限制都适用于此处,包括返回 100K 个或更少字符以及 45 秒超时。
ChatGPT 步骤
自定义 GPT 说明
创建自定义 GPT 后,将下面的文本复制到“Instructions”面板中。有疑问?查看 入门示例,了解此步骤如何更详细地工作。
You are a Q&A helper that helps answer users questions. You have access to a documents repository through your API action. When a user asks a question, you pass in the "searchTerm" a single keyword or term you think you should use for the search.
****
Scenario 1: There are answers
If your action returns results, then you take the results from the action and try to answer the users question.
****
Scenario 2: No results found
If the response you get from the action is "No results found", stop there and let the user know there were no results and that you are going to try a different search term, and explain why. You must always let the user know before conducting another search.
Example:
****
I found no results for "DEI". I am now going to try [insert term] because [insert explanation]
****
Then, try a different searchTerm that is similar to the one you tried before, with a single word.
Try this three times. After the third time, then let the user know you did not find any relevant documents to answer the question, and to check SharePoint.
Be sure to be explicit about what you are searching for at each step.
****
In either scenario, try to answer the user's question. If you cannot answer the user's question based on the knowledge you find, let the user know and ask them to go check the HR Docs in SharePoint. OpenAPI 架构
创建自定义 GPT 后,将下面的文本复制到“Actions”面板中。有疑问?查看 入门示例,了解此步骤如何更详细地工作。
这期望响应与我们的文档 此处 中的文件检索结构相匹配,并传入 searchTerm 参数以告知搜索。
请务必根据上面屏幕截图复制的链接切换函数应用程序名称、函数名称和代码
openapi: 3.1.0
info:
title: SharePoint Search API
description: API for searching SharePoint documents.
version: 1.0.0
servers:
- url: https://{your_function_app_name}.azurewebsites.net/api
description: SharePoint Search API server
paths:
/{your_function_name}?code={enter your specific endpoint id here}:
post:
operationId: searchSharePoint
summary: Searches SharePoint for documents matching a query and term.
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
searchTerm:
type: string
description: A specific term to search for within the documents.
responses:
'200':
description: A CSV file of query results encoded in base64.
content:
application/json:
schema:
type: object
properties:
openaiFileResponseData:
type: array
items:
type: object
properties:
name:
type: string
description: The name of the file.
mime_type:
type: string
description: The MIME type of the file.
content:
type: string
format: byte
description: The base64 encoded contents of the file.
'400':
description: Bad request when the SQL query parameter is missing.
'413':
description: Payload too large if the response exceeds the size limit.
'500':
description: Server error when there are issues executing the query or encoding the results.身份验证说明
以下是有关使用此第三方应用程序设置身份验证的说明。有疑问?查看 入门示例,了解此步骤如何更详细地工作。
有关身份验证的更详细说明,请参见上文和 Azure 函数 cookbook。
常见问题解答和故障排除
-
为什么在您的代码中使用 Microsoft Graph API 而不是 SharePoint API?
- SharePoint API 是旧版 - 根据 Microsoft 文档 此处,“对于 SharePoint Online,使用 REST API 对 SharePoint 进行创新是通过 Microsoft Graph REST API 驱动的。” Graph API 为我们提供了更大的灵活性,并且 SharePoint API 仍然遇到 为什么必须这样做而不是直接与 Microsoft Graph API 交互? 部分中列出的相同文件问题。
-
这支持哪些类型的文件?
它遵循与 此处 关于文件上传的文档相同的指南。
-
为什么需要请求 OBO 令牌?
-
当您尝试使用与 Azure 函数身份验证相同的令牌来验证 Graph API 时,您会收到“无效受众”令牌。这是因为令牌的受众只能是 user_impersonation。
-
为了解决这个问题,该函数使用 代表流 请求一个在应用程序中作用域为 Files.Read.All 的新令牌。这将继承登录用户的权限,这意味着此函数将仅搜索登录用户有权访问的文件。
-
我们特意在每次请求时都请求一个新的“代表”令牌,因为 Azure 函数应用程序旨在是无状态的。您可以将此与 Azure Key Vault 集成,以存储密钥并以编程方式检索密钥。
-
您希望我们优先考虑哪些集成?我们的集成中是否存在错误?在我们的 github 中提交 PR 或 issue,我们将进行查看。