简介
本指南适用于希望赋予 ChatGPT 使用 GPT Action 查询 SQL 数据库能力的开发者。在阅读本指南之前,请先熟悉以下内容
本指南概述了通过中间件应用程序将 ChatGPT 连接到 SQL 数据库所需的工作流程。我们将使用 PostgreSQL 数据库作为示例,但此过程对于所有 SQL 数据库(MySQL、MS SQL Server、Amazon Aurora、Google Cloud 上的 SQL Server 等)都应类似。本文档概述了创建 GPT Action 所需的步骤,该 GPT Action 可以
- 执行针对 SQL 数据库的读取查询
- 通过文本响应返回记录
- 通过 CSV 文件返回记录
价值 + 示例业务用例
价值:用户现在可以利用 ChatGPT 的自然语言能力来回答有关 SQL 数据库中数据的问题
- 业务用户无需编写 SQL 或向分析师提交请求即可访问 SQL 数据库中包含的信息
- 数据分析师可以通过提取数据并使用 ChatGPT 进行分析,从而执行超出 SQL 查询可能实现的复杂分析
示例用例:
- 业务用户需要回答有关其销售渠道的问题
- 数据分析师需要对大型数据集执行回归分析
应用程序设计考虑因素
鉴于大多数托管 SQL 数据库不提供用于提交查询的 REST API,您将需要一个中间件应用程序来执行以下功能
- 通过 REST API 请求接受数据库查询
- 将查询转发到集成的 SQL 数据库
- 将数据库响应转换为 CSV 文件
- 将 CSV 文件返回给请求者
设计第一个功能主要有两种方法
- 中间件支持一种接收 GPT 生成的任意 SQL 查询并将其转发到数据库的单一方法。这种方法的优点包括
- 易于开发
- 灵活性(不需要您预测用户将提出的查询类型)
- 低维护(不需要您响应数据库更改而更新 API 架构)
- 中间件支持多种与特定允许查询相对应的方法。这种方法的优点包括:4. 更多控制 5. 减少模型在生成 SQL 时出错的机会
本指南将重点介绍选项 1。对于那些对选项 2 感兴趣的人,请考虑实施像 PostgREST 或 Hasura 这样的服务来简化流程。
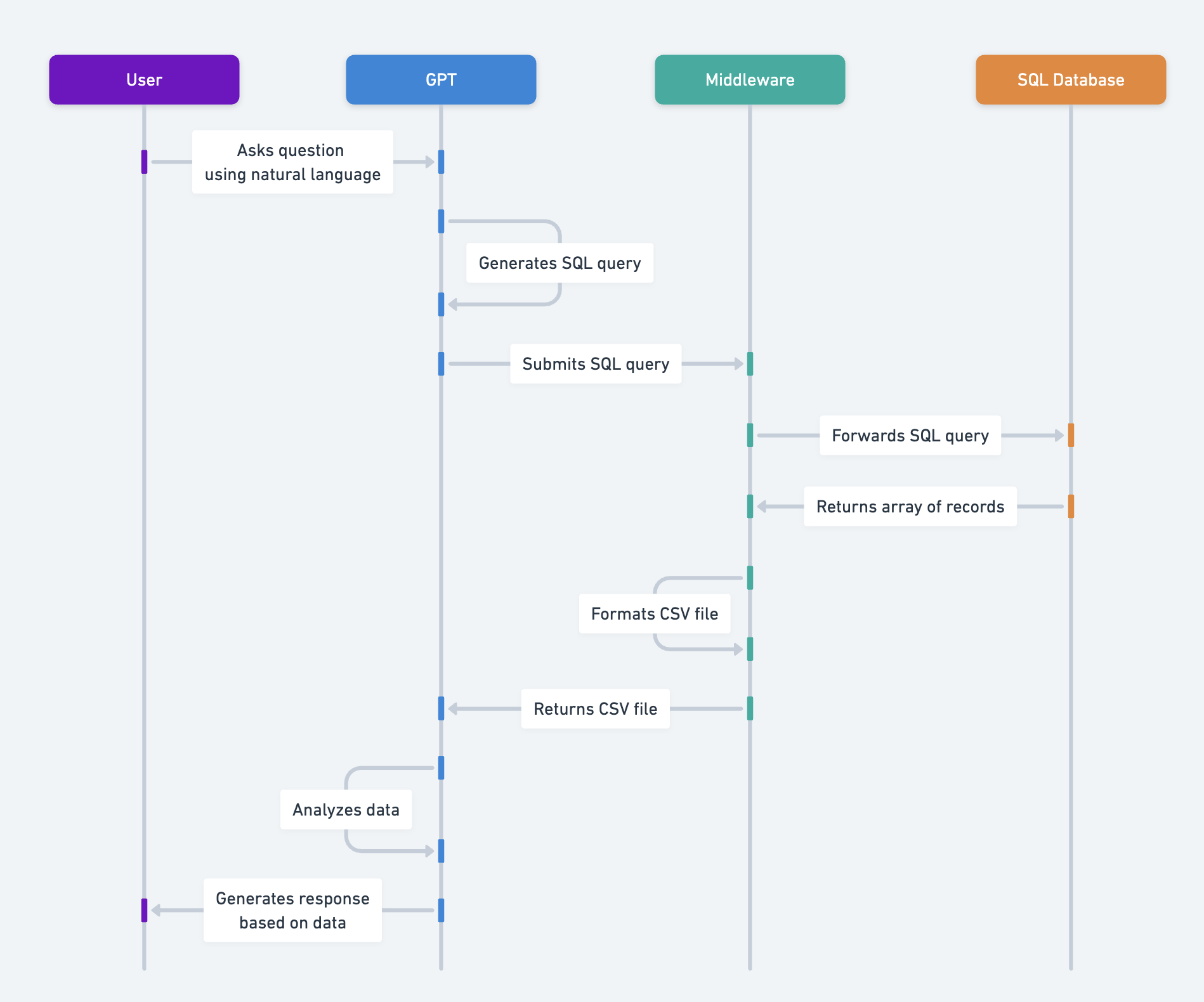 应用程序架构图
应用程序架构图
中间件注意事项
开发者可以构建自定义中间件(通常部署为具有 AWS、GCP 或 MS Azure 等 CSP 的无服务器函数)或使用第三方解决方案(如 Mulesoft Anypoint 或 Retool Workflows)。使用第三方中间件可以加速您的开发过程,但不如自己构建灵活。
构建自己的中间件使您可以更好地控制应用程序的行为。有关自定义中间件的示例,请参阅我们的 Azure Functions cookbook。
本指南将重点介绍中间件与 GPT 和 SQL 数据库的接口,而不是关注中间件设置的具体细节。
工作流程步骤
1) GPT 生成 SQL 查询
GPT 非常擅长根据用户的自然语言提示编写 SQL 查询。您可以通过以下方式之一让 GPT 访问数据库架构,从而提高 GPT 的查询生成能力
- 指示 GPT 首先查询数据库以检索架构(我们的 BigQuery cookbook 中更详细地演示了这种方法)。
- 在 GPT 指令中提供架构(最适合小型、静态架构)
以下是包含有关简单数据库架构信息的示例 GPT 指令